Scaling Databases
Lets talk about how we can scale database !
So as you might be aware, there are two types of scaling.
-
Vertical Scaling - This is where you increase the memory and computer power for a single DB server. This enables us to store more data and serve more queries.
-
Horizontal Scaling - Vertical scaling has physical limits and it becomes a single point of failure. You can overcome these limitations by doing horizontal scaling, where you add more DB servers to the DB cluster. And the good thing is you can keep adding more servers to the cluster as you need them.
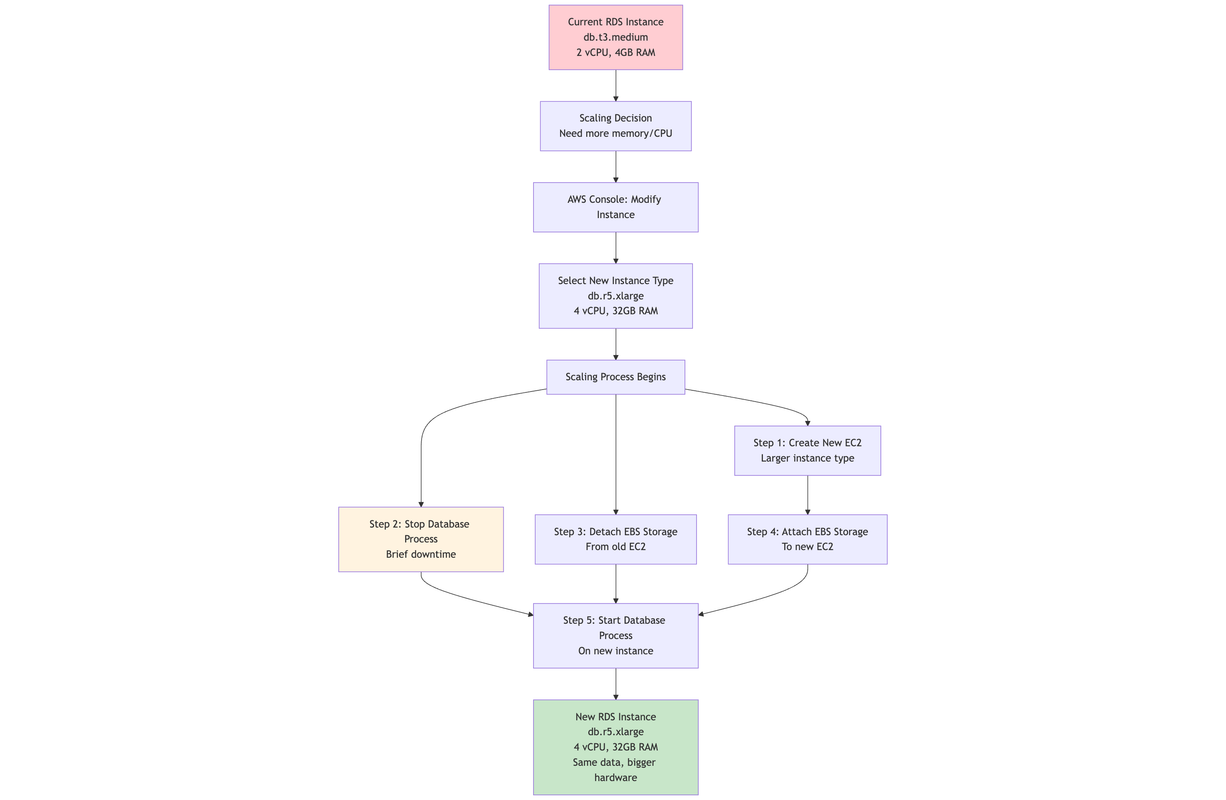
Here's what actually happens when you try to scale db in aws cloud -
Database partitioning
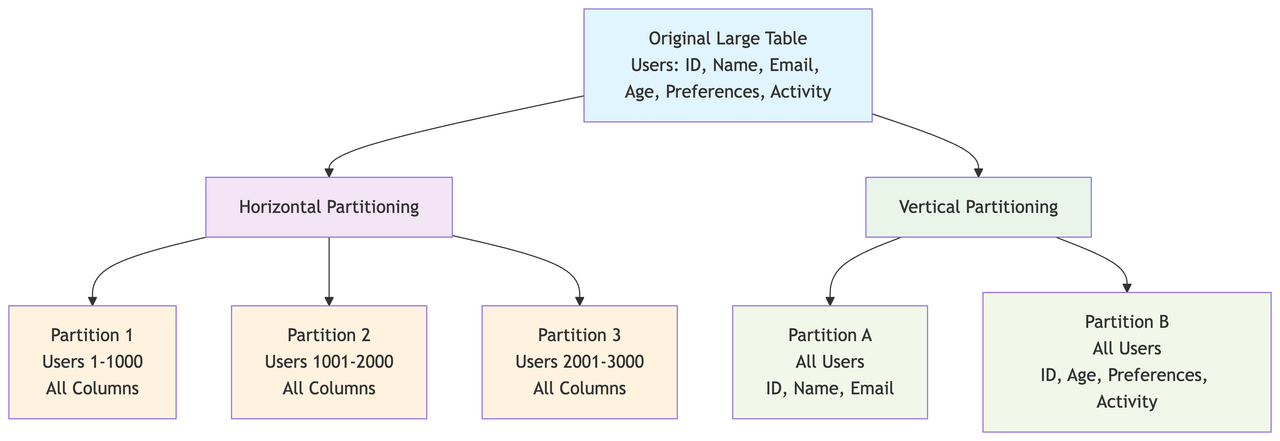
Partitioning is like splitting. Imaging curring a cake. Either you can cut it vertically or you can layer by layer horizontally.
This is a vertical scaling technique where you split the table into partitions but keep them in the same database.
Each partition contains a subset of data. These data subsets are created based on various factors like date range, geographic location, or some specific column values.
Imagine a massive phone book. Instead of one gigantic book, you could divide it into sections based on the first letter of the last name (A-M, N-Z). Each of these sections is a partition, and they all exist as part of your overall phone book system.
Vertical partitioning improves query performance and manageability (indexing, backups, etc.)
The real reason we do partitioning is because the table is getting too big ( > 10m rows ) our reads are accessing only subset of table data.
Doesn't partitioning looks like normalization ?
You might get that feeling ! But there's a subtle difference. You would generally do normalization to reduce/avoid data redundancy and ensure data integrity in your tables.
You would do vertical partioning only for optimizing the query performance. So lets for a given table with 10 attributes/columns, you observe that there are 3 columns which your queries are fetching, you would use partitioning to split the table into two tables - one containing only the frequently fetched 3 attrubtes and second containing the rest.
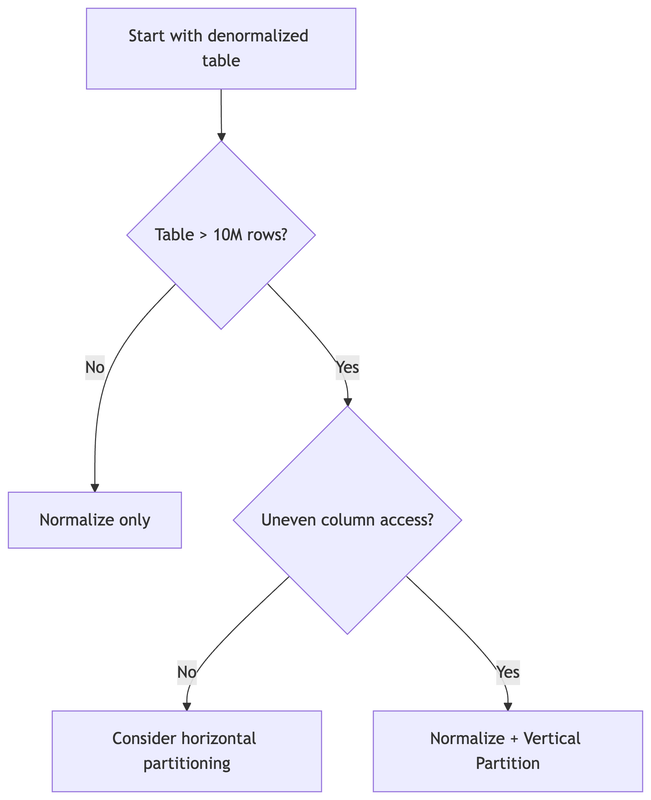
Thumb rule : Normalize until JOINs hurt performance → then partition.
Handling Joins with partitions
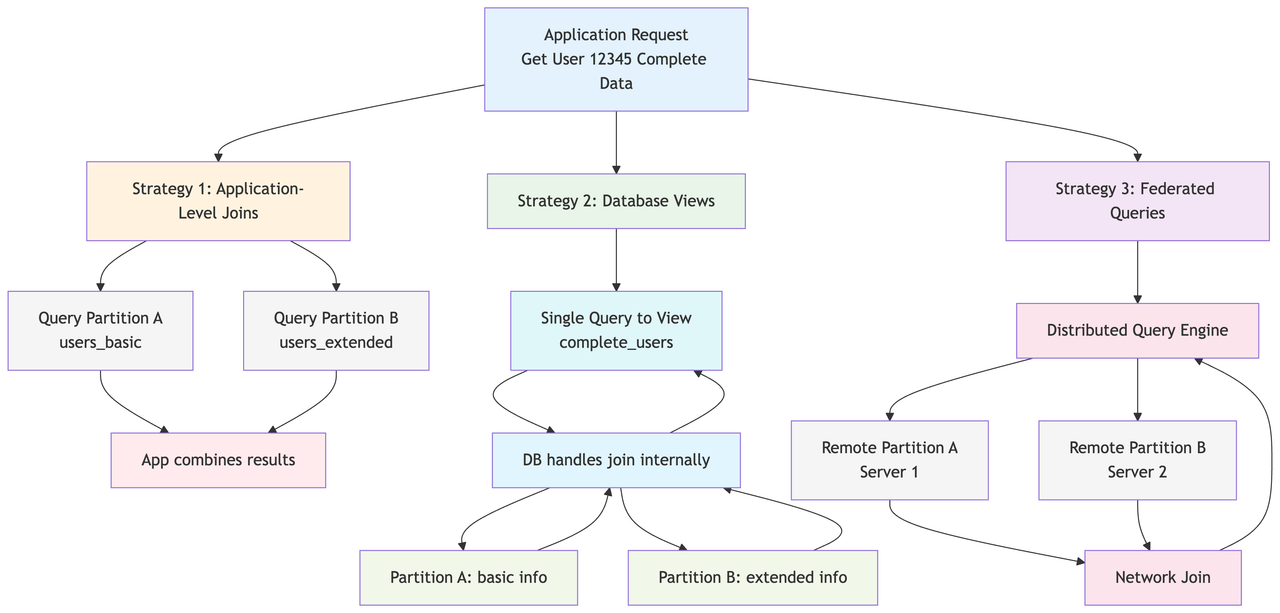
- Application level joins
The database doesn't automatically handle cross-partition joins. Instead, your application code performs multiple queries:
Pros: Full control, can optimize per use case Cons: More complex application logic, multiple round trips
- Database views
When both partitions are on same database server, you can create views for your join queries. And then your application service can fetch data from these views.
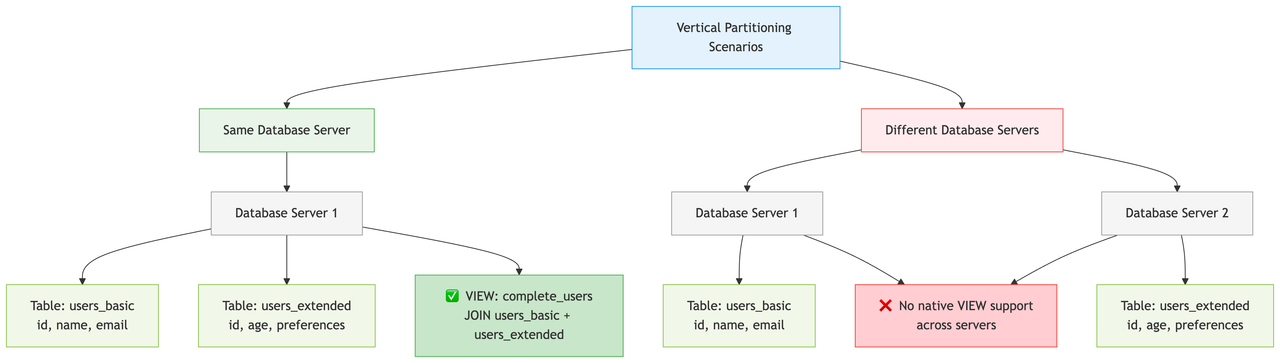
Pros: Transparent to application Cons: Only works when partitions are on same database server
- Federated queries
Federated queries allow querying data from multiple, physically separate databases as if they were a single database. Instead of moving data to a central location, the query engine retrieves and combines results from remote sources on demand.
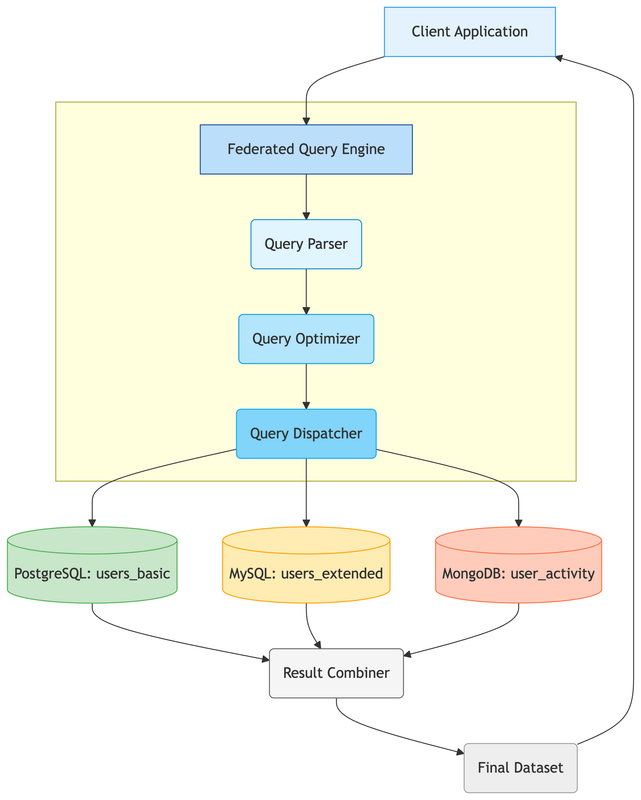
Database sharding
Sharding is a form of horizontal partitioning.
In sharding, we split the table rows across multiple database servers. Each server holds a subset of the data ie. a shard.
Think of our phone book example again. Sharding would be like having entirely separate phone books, each covering a different alphabetical range (A-M on one server, N-Z on another). To find a number, you need to know which phone book (shard) to look in.
When to use sharding ?
Use When
- Your database is too large for a single server (e.g., >500GB–1TB).
- Workloads are geographically distributed (e.g., users in the EU vs. US).
- You need linear scalability (e.g., social media apps with 100M+ users).
Avoid When
- Your dataset fits comfortably on one machine (e.g., < 100GB).
- You need complex cross-shard transactions (e.g., banking systems).
- Your queries cant be isolated to a shard (e.g., analytics requiring full scans).
Key componets of sharding
- Shared-nothing architecture
In a shared-nothing architecture, each shard is a separate database server. Data is distributed across these servers, and they don't share any resources.
- Shard key
The shard key is the column or combination of columns used to determine which shard a row belongs to.
- Routing mechanism
The routing mechanism is responsible for directing queries to the correct shard based on the shard key. This is either part of the application layer or a separate middleware.
Sharding strategies based on shard key
- Key based (Hash) based sharing
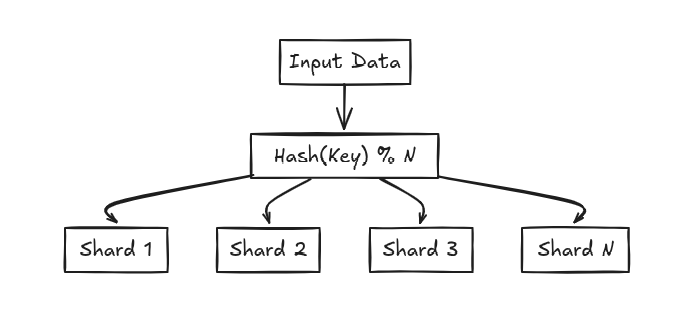
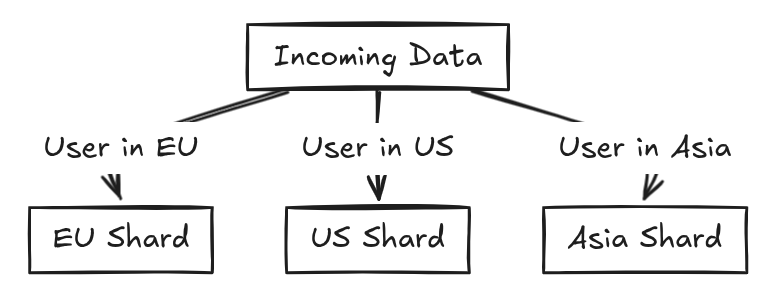
- Geo based sharding
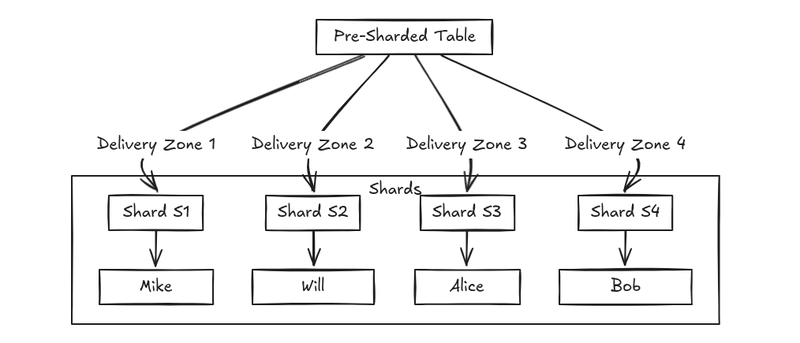
- Directory based sharding
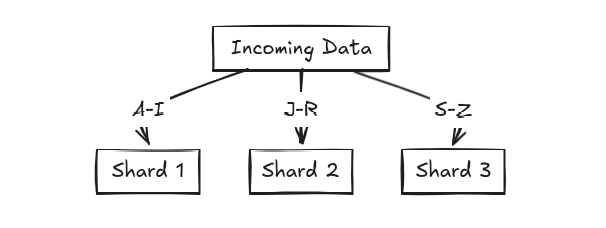
- Range based sharding
Comparison of sharding strategies
| Sharding Strategy | How It Works | Pros | Cons | Best For | Example Use Case |
|---|---|---|---|---|---|
| Key-Based (Hash) Sharding | Uses a hash function on shard key to distribute data |
|
| High-volume transactional systems | User profiles in social media apps |
| Range-Based Sharding | Splits data based on value ranges (dates, IDs) |
|
| Time-series and analytical data | Sales records by quarter |
| Directory-Based Sharding | Uses lookup service to map keys to shards |
|
| Systems needing flexible sharding | Multi-tenant SaaS applications |
| Geographic Sharding | Data partitioned by physical location |
|
| Global applications with local users | E-commerce with regional warehouses |
| Tenant-Based Sharding | Each customer gets dedicated shard(s) |
|
| SaaS and multi-tenant systems | CRM platforms with enterprise clients |
Guidelines for picking shard keys
- Pick a column with high cardinality i.e. many unique keys
- Pick a column which is immutable or rarely changes. This is required to ensure that we dont have to do resharding which is super expensive.
- Pick a column which minimizes cross-shard queries.
Sample Architecture with Sharding
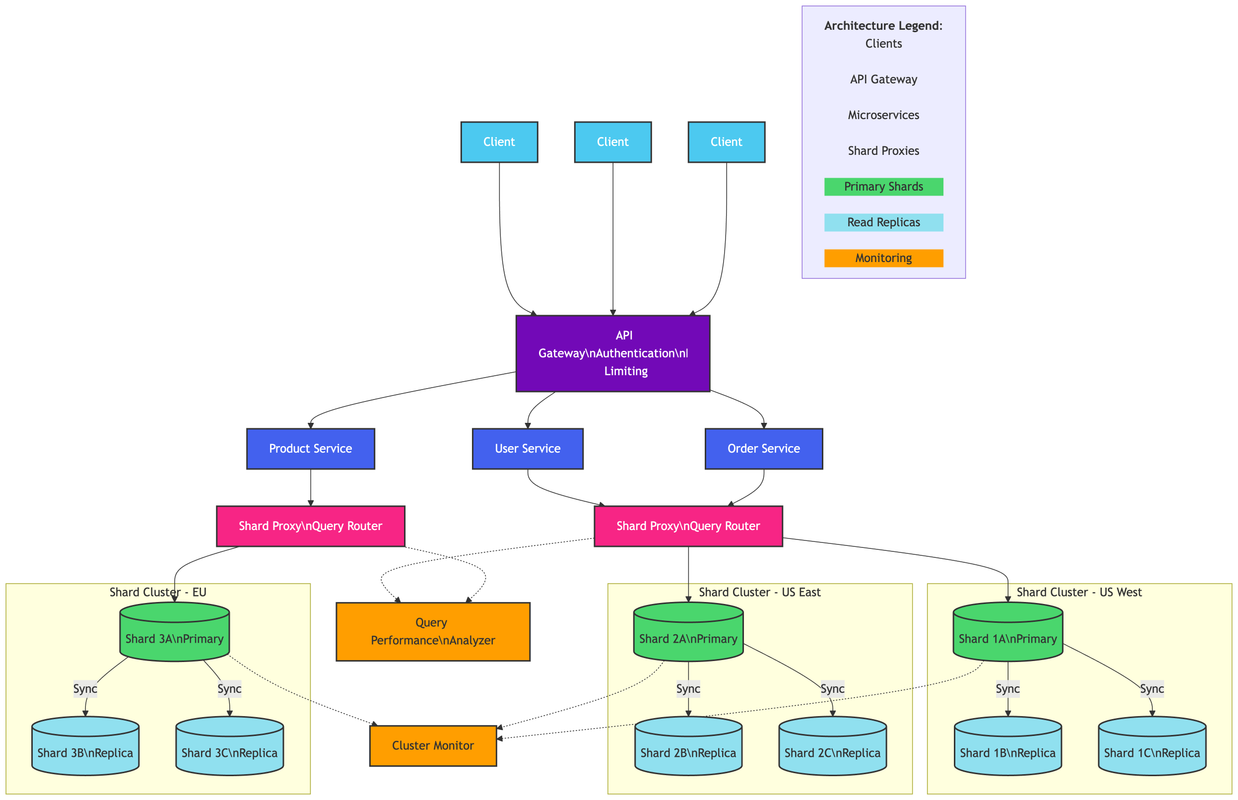
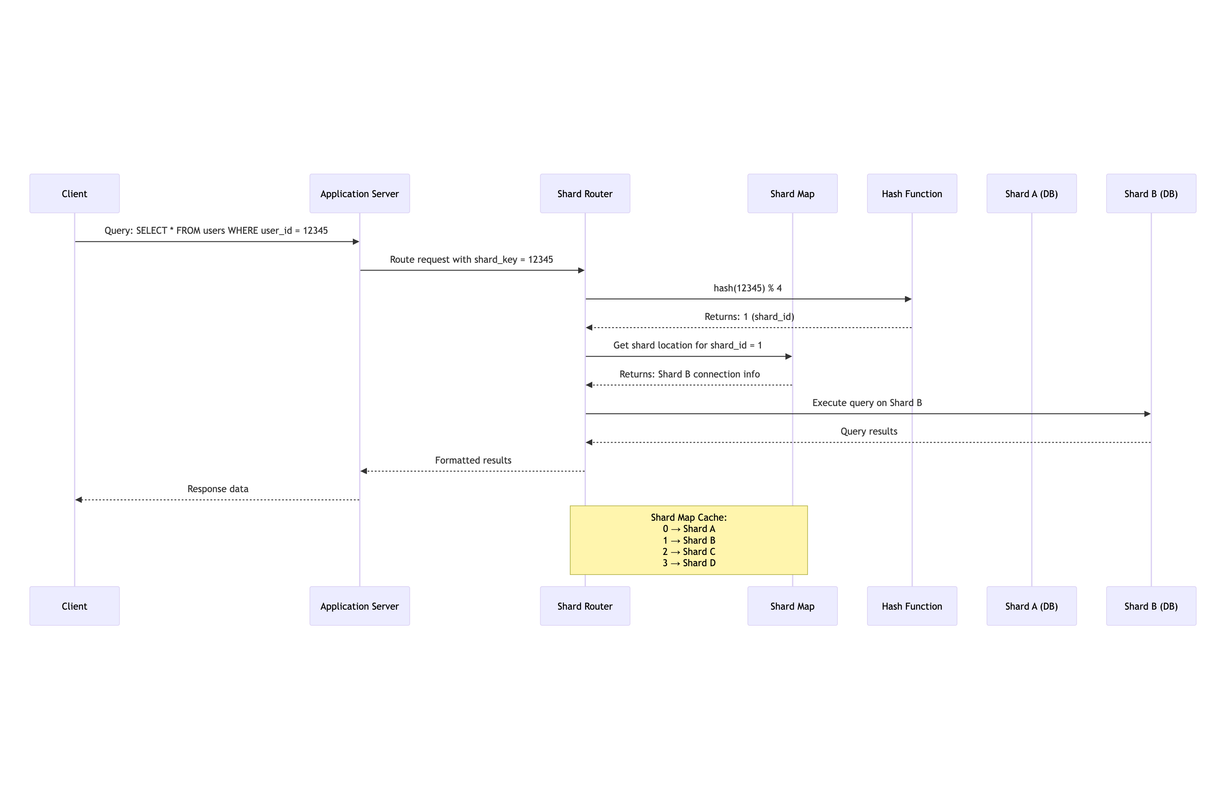
Sample request workflow with sharded database